 Historian
HistorianData Collectors Overview
About Historian Data Collectors
Many data collectors bring data into the Historian server, as listed in Supported Windows Versions for Historian Collectors.
Since installation, maintenance, and troubleshooting from a Historian perspective are essentially the same for all collectors other than the File collector, this chapter summarizes the characteristics of each and highlights their differences. It also provides a detailed description for the File collector, since it differs from the other types of collectors.
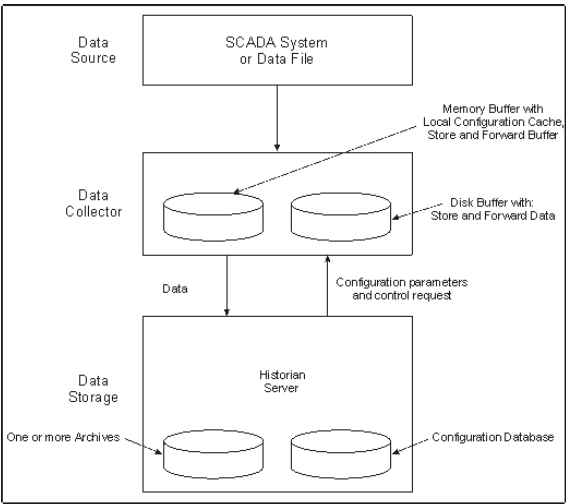
Data collectors use a specific data acquisition interface that match the data source type, such as iFIX Easy Data Access (EDA) or OPC 1.0 or 2.0 (Object Linking and Embedding for Process Control). For more information, see Supported Acquisition Interfaces. The Simulation collector generates random numeric and string data. The File collector reads data from text files.
| Collector Name | Is Toolkit-Based? | Consumes a CAL? |
|---|---|---|
| The Calculation collector | No | Yes |
| The Cygnet collector | Yes | Yes |
| The File collector | No | No |
| The iFIX Alarms and Events collector collector | No | No |
| The iFIX collector | No | No |
| The MQTT collector | Yes | Yes |
| The ODBC collector | Yes | Yes |
| The OPC Classic Alarms and Events collector | No | No |
| The OPC Classic HDA collector | Yes | Yes |
| The OPC UA DA collector | Yes | Yes |
| Th OPC UA Data Access (DA) collector | No | No |
| The OSI PI collector | No | No |
| The Server-to-Server collector | No | Yes |
| The Server-to-Server distributor | No | Yes |
| The Simulation collector | No | No |
| The Windows Performance collector | Yes | Yes |
| The Wonderware collector | Yes | Yes |
- When failover occurs from a primary collector to a secondary collector (or vice versa), there will be some data loss as the collector tries to connect to the source to fetch the data.
Bi-Modal Cloud Data Collectors
- The File collector
- The Calculation collector
- The Server-to-Server distributor
- The OSI PI Distributor
- The OPC Classic Alarms and Events collector
- The iFIX Alarms and Events collector
The Predix cloud destination (via a secure Web socket) supports APM, Automation, or Brilliant Manufacturing Cloud subscription. The Collector Toolkit is updated as well. Hence, a custom collector created using the toolkit has the same capabilities.
All the features available in the Historian Data Collectors are applicable to cloud collectors. The features such as tag configuration, store and forward, compression, recalculation are all available in cloud collectors if same functionality is available in the same data collector sending data to Historian. See Historian Data Collectors for additional information.
There are a few differences in the working of a Bi-Modal collector based on whether the destination is Historian or cloud. Following table explains the key differences.
| Functionality | Destination - Historian | Destination - Cloud |
|---|---|---|
| HISTORIANNODENAME registry key | Contains the destination Historian Server???s name/ IP Address. |
Contains the cloud destination settings as well as proxy historian server name or IP if applicable (configServer). Cloud destination format:
|
|
Mapping Source Tags with Destination Tags (Add Tags) |
You must map tags in Historian Server to Data Source tags using one of the Admin tools (VB Admin/Web Admin). The data gets stored in IHA files and the Tag configurations are stored in IHC files. |
As it is not possible to map tags in the Cloud with tags in the Data Source, user must select if mapping should be done through Historian (works as a proxy) or through Offline Configuration File at the time of installation. If the user selects Historian, then tags will be created in the Cloud which in turn may have been mapped through one of the Admin tools (VB Admin/Web Admin). If Offline Configuration File is selected, the user must provide an XML configuration file containing tag configurations that need to be created in the Cloud for mapping them with the Source tags. |
| Other Tag Management Operations such as Delete, Rename, Data cleaning | It is possible to do all tag management operations. | No tag management operations are allowed. After you update the offline tag configuration file, or after you specify the tags using Historian Administrator, the changes are reflected automatically (without the need to restart the collector). |
| Data Type support | All standard data types are supported. | All other data types, excepting arrays, enums and User defined types (UDT), BLOB, are supported. |
Data Collector Software Components
- Data Collector Program
Executable data collection program for the type of collector. For example, ihFileCollector.exe.
- Local Tag Cache
Cache of configuration information that permits the collector to perform collection even when the archiver is not present at start-up (*.cfg).
- Local Outgoing Data Buffer
Buffer of the data sent to the server that the server has not yet confirmed receiving.
- Historian API
Interface that connects the collector to the Historian Server for configuration, data flow, and control functions.
Supported Windows versions for Data Collectors
The following table displays the supported Windows processor versions (32-bit or 64-bit) for the Historian data collectors.
| Collector Name | 32-bit | 64-bit |
|---|---|---|
| The Calculation collector | Yes | Yes |
| The Cygnet collector | No | Yes |
| The File collector | Yes | Yes |
| The iFIX Alarms and Events collector collector | Yes | Yes |
| The iFIX collector | Yes | Yes |
| The OPC Classic Alarms and Events collector | Yes | Yes |
| The OPC DA collector | Yes | Yes |
| The OPC Classic HDA collector | No | Yes |
| The OPC UA Data Access (DA) collector | No | Yes |
| The OSI PI collector (API / SDK) | Yes | Yes |
| The OSI PI distributor | Yes | Yes |
| The Server-to-Server collector | Yes | Yes |
| The Server-to-Server distributor | Yes | Yes |
| The Simulation collector | Yes | Yes |
| The Windows Performance collector | Yes | Yes |
| The Wonderware collector | No | Yes |
| The ODBC collector | No | Yes |
| The MQTT collector | No | Yes |
Data Collector Functions
- Connects to the data source using a specific data acquisition interface, such as EDA, OPC 1.0, or OPC2.0.
- Groups tags by collection interval for efficient polling.
- Reads data as frequently as 10 times/sec, depending on the configuration parameters of individual tags. An OPC Collector configured for unsolicited collection can read data as frequently as 1 millisecond (or 1000 times/second).
- Scales the collected value to the EGU Range.
- Compresses collected data based on a deadband specified on a tag by tag basis, and forwards only values that exceed the deadband to the Historian Server for final compression and archiving.
- Automatically stores data during a loss of connection to the server and forwards that data to the server after the connection is restored.
Common Collector Functions
- Maintains a local cache of tag information to sustain collection while the server connection is down.
- Automatically discovers available tags from a data source and presents them to Historian Administrator.
- Buffers data during loss of connection to the server and forwards it to the server when the connection is restored.
- Automatically adjusts timestamps, if enabled, for synchronizing collector and archiver timestamps.
- Supports both collector and device timestamping, where applicable.
- Schedules data polling for polled collection.
- Performs first level of data compression (collector compression).
- Responds to control requests, such as pause/resume collection.
After collecting and processing information, a collector forwards the data to the Historian Server, which optionally performs final compression and stores the information in the Archive Database. The Archive Database consists of one or more files, each of which contains a specific time period of historical data. For more information on Historian Server architecture, refer to Historian System Architecture.
File collector Functions
The File collector imports files in either CSV (Comma Separated Variables) or XML (Extensible Markup Language) format. Since this is basically a file transfer operation, a File collector does not perform the typical collector functions of data polling, browsing for tags, pause/resume collection, data compression, or storing/forwarding of data on loss of server connection. A File collector, however, is an extremely useful tool for importing and configuring tags, for bulk updating of tag parameters and messages, and for importing data from all types of systems.
Supported Acquisition Interfaces
| Data Collector | Data Acquisition Interface |
|---|---|
| iFIX Data Collector | EDA data acquisition interface |
| Machine Edition View Data Collector | Point Management API Interface |
| OPC Data Collector | OPC data acquisition interface |
| OPC Classic Alarms and Events collector | The OPC Alarms and Events server |
| File Data Collector | CSV or XML file import |
| Simulation Data Collector | Random pattern of data |
| Calculation collector | Calculations performed on data already in the server |
| Server-to-Server Collector | Data and messages collected from one Historian Server (source) to another Historian Server (destination) |
| OPC UA Data Access (DA) collector | OPC Data Acquisition interface for Microsoft Windows |
| Wonderware Data Collector | SQL Server ODBC Driver Interface |
| Cygnet collector | SQL Server ODBC Driver Interface |
| ODBC collector | SQL Server ODBC Driver Interface |
Best Practices for Working with Data Collectors
- Synchronize the Windows clock for the following computers:
- Source Data Archiver of a Server-to-Server Collector
- Computer on which the Data Collector is running
- Destination Data Archiver
- Turn on the Data Recovery Mode option for Historical Collectors such as Server-to-Server and Calculation collectors. This ensures that most gaps in data collection due to the unavailability of source Archiver or in the case of collector not running are automatically filled in the next time the collector runs.
- If you are using polled collection with Calculation or Server-to-Server Collector, ensure that you have at least one uncompressed polled tag so that the polled data is frequently sent to the destination Archiver. This ensures that the bad data marker sent when a collector shuts down has an accurate time stamp that reflects the time of shutdown of the collector.




