 Historian
HistorianOverview
Overview of the Historian Server-to-Server Collector
The Historian Server-to-Server collector allows you to collect data and messages from a source Historian server to a destination Historian server, a Predix Time Series instance, an Azure IoT HUb instance, or an MQTT endpoint such as AWS IoT Core. The Server-to-Server collector includes many of the features of the Calculation collector. The primary difference is that the Server-to-Server collector stores the result in a destination tag on the destination server, whereas the Calculation collector reads and writes to the same server.
The Server-to-Server collector can also run as a stand-alone component where both the source and destination Historian databases are on remote machines.
- The calculation formula for the destination tag is executed.
This typically involves fetching data from one or more tags on the source server.
- A raw sample or calculation error is determined.
You can use conditional logic in your calculation formula to determine if a sample should be sent to the destination.
- The raw sample is delivered to the destination server, utilizing store and forward when necessary.
Message replication, if enabled, is event-based. Messages and alerts are sent to the destination server as they happen.
- When a tag is added by browsing, only certain tag properties are copied from the source tag to the destination tag. Consider what properties are necessary for your application and configure them manually. For information on which properties are copied, refer to Tag Properties that are Copied.
- If you change a tag property on the source tag (EGU Limits, descriptions, and so on), the property does not automatically change on the destination tag. You can manually change the properties of a destination tag.
Data Flow in Multiple Server-to-Server Collectors
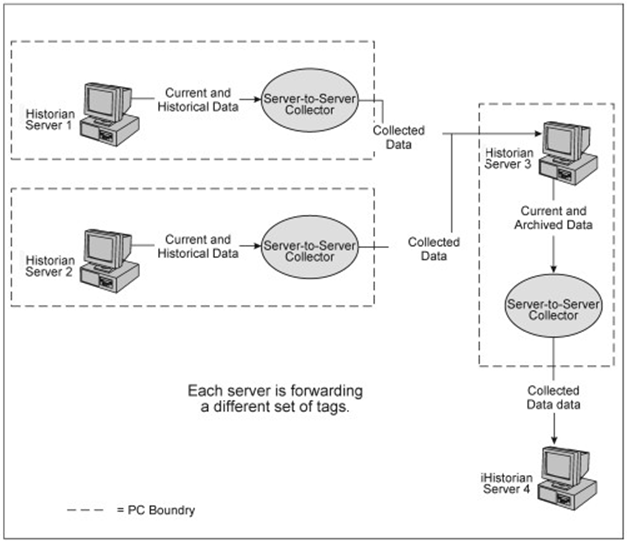
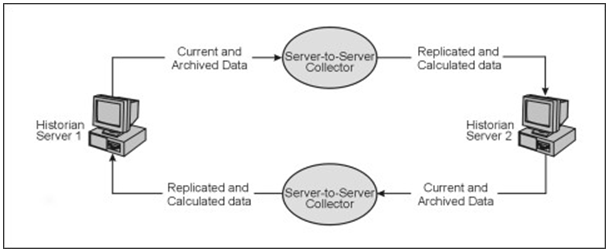
Data Flow in Bi-directional Server-to-Server Collectors
| Feature | Capability |
|---|---|
| Browse Source for Tags | Yes |
| Browse Source for Tag Attributes | Yes |
| Polled Collection | No |
| Minimum Poll Interval | No |
| Unsolicited Collection | Yes |
| Timestamp Resolution | Yes - 100 milliseconds |
| Data Compression | Yes |
| Accept Device Timestamps | Yes |
| Floating Data Point | Yes |
| Integer Data | Yes |
| String Data | Yes |
| Binary Data | No |
| Allows VB scripting | No |
| Python Expression Tags | No |
Licensing
When the destination server is Proficy Historian, the Server-to-Server collector requires licensing on the destination machine. This means that the destination Historian server must be licensed for the Historian Enterprise edition, have the Enterprise Collectors option licensed, or be a Historian Edge server. It is similar to any other collector. The destination machine will have the Server-to-Server listed in its collector list.
Interface Name
<source Historian server>_To_<destination Historian server>- We recommend that you install the Server-to-Server collector on the source Historian machine. When you do so, the collector can preserve the collected data (store and forward) even if the collector and the destination server become disconnected.
- Collection on a tag-by-tag basis is preferred, according to scheduled poll times or upon data changes. One sample is collected for each trigger.
- The Server-to-Server collector can perform calculations on multiple input tags as long as the input tags are on the same source Historian.
- Use polled triggers to perform scheduled data transformations like daily or hourly averages. Use unsolicited triggers to replicate data in real time, as it changes.
- Use event-based triggers to replicate data throughout the day. The samples can be held ingoing an outgoing store and forward buffer when necessary. You cannot schedule batch replication of raw samples. For example, you cannot, at the end of the day, send all raw samples for tags to the destination.
- All input source tags for the calculations must originate from the source
archiver. For instance, you cannot directly add a tag from
server1plus a tag fromserver2and place the result onserver2. You could, however, collect tags fromserver1toserver2, and then use the Calculation collector or the Server-to-Server collector to accomplish this. This requires two Server-to-Server collectors, one running on each machine. You could also use the Historian OLE DB provider.
- If you enable alarm replication, the alarm data is sent to the destination server. However, alarm filtering is not available in the Server-to-Server collector.
- You cannot configure bi-directional message replication.
About Recovery Mode
Normally, the Server-to-Server collector operates in a real-time mode. A real-time mode is when the collector is polling data or has subscribed to events and triggers calculations based on these events occurring in real-time. Messages are also sent as they occur. Recovery mode allows you to recover tag and alarm data when the connection between the collector and the source server is re-established. After a connection loss, the configuration settings for the Server-to-Server collector determine how much tag and alarm data is recovered and if messages are included in the recovery.
When Does Recovery Occur?
- When the collector is started.
- When the collector is resumed after a pause.
- When there is an on-the-fly change (similar to a pause and resume). Only tags in the new tag configuration are recovered.
- When there has not been a collector stop and start, but the connection to the source Historian is restored.
What Happens When Recovery Occurs?
- Set up subscriptions for all alarms and trigger tags.
- Perform recovery in chronological order (oldest to newest).
- Perform message recovery, if enabled.
- Begin polling and processing subscriptions in real-time mode.
- Event-based tags: This includes the data from the last write time until now. The system retrieves all tags.
- Messages: The system checks for new messages and verifies errors. Once the system verifies a connection to the destination, it sends the messages one at a time.
- Alarm data: This includes all alarm data from the last write time until now.
If your formula contains tags not in the trigger list or dependencies exist among tags (for example, if a calculation tag is a trigger for another calculation tag), you might not recover all data.
About Collection of Raw Samples
To minimize the effect of missing samples, we recommend that you view collected data on the destination with interpolated queries rather than raw data queries.
- Use the formula
Result=CurrentValue("TriggerTag"). - Do not use collector compression on the destination tag.
- Use archive compression on the destination if it is set on the source.
The reason for this is that unsolicited triggers occur based on value changes, not based on what is stored in the archive. A value change may not be stored on the destination if archive compression is being used. It is up to the destination tag to apply the archive compression before the value is stored.
- Use event-based triggers with
0 mscollection intervals. - In the Server-to-Server collector, disable the Synchronize Timestamps to Server option in the Advanced section in the collector configuration in Historian Administrator.




