 Historian
HistorianOverview of Historian
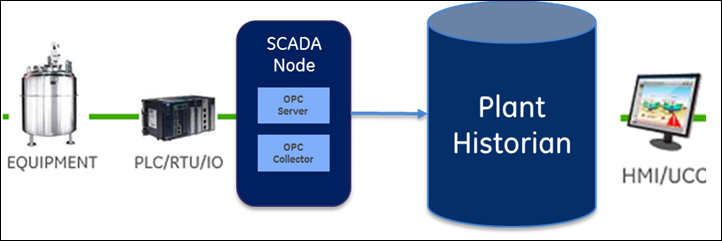 You
can collect data from multiple SCADA systems and various applications, and store them in
a central Proficy Historian server.
You
can collect data from multiple SCADA systems and various applications, and store them in
a central Proficy Historian server.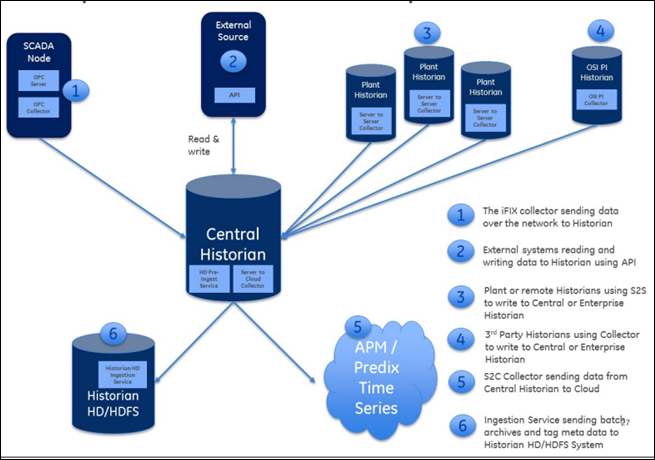
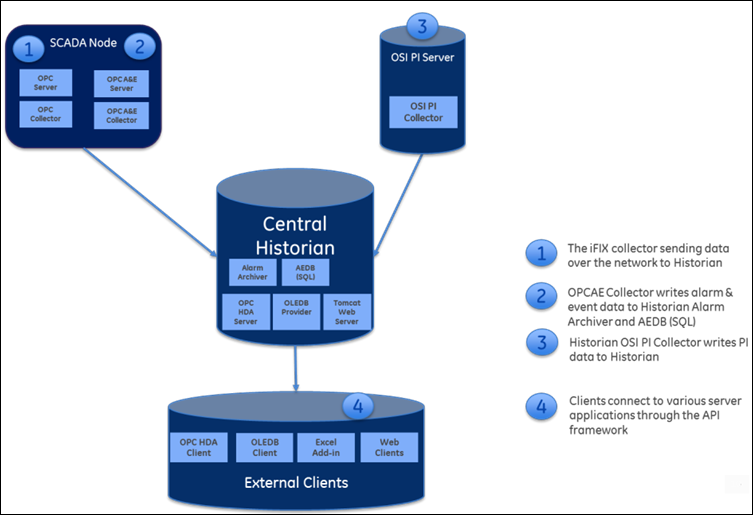
- Data collectors: Collect and analyze the tag data.
- The Historian server: Stores tag data.
- Clients: Retrieve tag data from the Historian server using APIs.
- Data Collectors
- Collectors are applications that collect data from a wide variety of
applications such as iFIX, CIMPLICITY, OPC servers, OSI PI, and text files
(.csv or .xml). This data is then stored in the Historian server.
In addition, Historian contains the Calculation and the Server-to-Server collectors. The Calculation collector performs calculations and analyses on Historian data and stores the results in tags on the server. The Server-to-Server collector has the same calculation capabilities as the Calculation collector, but it stores the results in tags on a remote server.
Most collectors can perform first-order deadband compression, a browse-and-add configuration, and store and forward buffering.
Note: Standard collectors that are included as part of the product will not consume a client-access license (CAL). Other interfaces developed by customers or system integrators using the Collector Toolkit or APIs will consume a CAL for each instance or connection.Bi-Modal Collectors:
The Historian data collectors can send data to an on-premises Historian server as well as cloud destinations such as Google Cloud, Azure IoT Hub, AWS Cloud, and Predix Cloud. Therefore, these collectors are called bi-modal collectors. The following collectors, however, are not bi-modal collectors; they can send data only to an on-premises Historian server:- The Calculation collector
- The File collector
- The HAB collector
- The iFIX Alarms and Events collector
- The OPC Classic Alarms and Events collector
- The OSI PI Distributor
- The Python collector
- The Server-to-Server distributor
- The Historian Server
-
The Historian server is the central point for managing all of the client and collector interfaces, storing data and (optionally) compressing and retrieving data.
In the Historian server, data is stored in files called data archives. These files contain all the tag data gathered during a specific period of time (for example, time-based archives such as daily archives). They have the .iha extension.
You can store data of various data types such as Float, Integer, String, Byte, Boolean, Scaled, and binary large object data type (BLOB). The source of the data defines the ability of Historian to collect specific data types. If you have the license to store the alarms and events data, the server also manages the storage and retrieval of OPC Alarms and Events in a SQL Server Express.
You can further segregate your tags and archives into data stores. A data store is a logical collection of tags used to store, organize, and manage tags according to the data source and storage requirements. A data store can have multiple data archives, and includes logical and physical storage definitions.
The primary use of data stores is segregating tags by data collection intervals. For example, you can put name plate or static tags where the value rarely changes in one data store, and put process tags in another data store. This can improve the query performance.
The Historian Data Archiver is a service that indexes all the data by tag name and timestamp and stores the result in an .iha file. The tag name is a unique identifier for a tag (which is a specific measurement attribute). For iFIX users, a Historian tag name normally represents a Node.Tag.Field (NTF). Searching by the tag name and time range is a common and convenient way to retrieve data from Historian. If you use this technique to retrieve data from the archive files, you need not know which archive file contains the data. You can also retrieve data using a filter tag.
- Clients
- Clients are applications that retrieve data from the archive files using the Historian API. The Historian API is a client/server programming interface that maintains connectivity to the Historian Server and provides functions for data storage and retrieval in a distributed network environment.