Archive Storage
Historian stores up to 1200 seconds of future data.
Archive Compression Overview
The Data Archiver performs archive compression procedures to conserve disk storage space. Archive compression can be used on tags populated by any method (collector, migration, file collector, SDK programs, Excel, etc.)
Archive compression is a tag property. Archive compression can be enabled or disabled on different tags and can have different deadbands.
Archive compression applies to numeric data types (scaled, float, double float, integer and double integer). It does not apply to string or blob data types. Archive compression is useful only for analog values, not digital values.
Archive compression can result in fewer raw samples stored to disk than were sent by collector.
If all samples are stored, the required storage space cannot be reduced. If we can safely discard any samples, then some storage space can be reduced. Briefly, points along a straight or linearly sloping line can be safely dropped without information loss to the user. The dropped points can be reconstructed by linear interpolation during data retrieval. The user will still retrieve real-world values, even though fewer points were stored.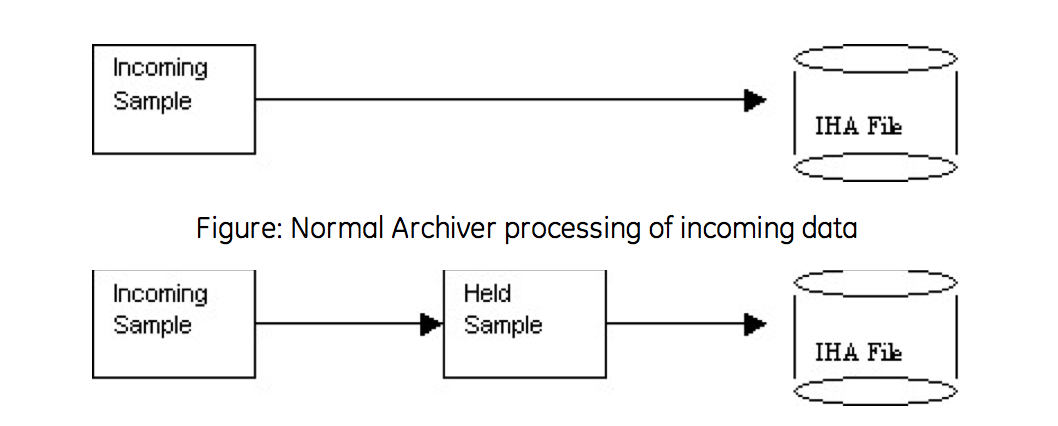
Archive Compression uses a held sample. This is a sample held in memory but not yet written to disk. The incoming sample always becomes the held sample. When an incoming sample is received, the currently- held sample is either written to disk or discarded. If the currently-held sample is always sent to disk, no compression occurs. If the currently-held sample is discarded, nothing is written to disk and storage space is conserved.
In other words, collector compression occurs when the collected incoming value is discarded. Archive compression occurs when the currently-held value is discarded.
Held samples are written to disk when archive compression is disabled or the archiver is shut down.
Archive Compression Logic
IF the incoming sample data quality = held sample data quality
IF the new point is a bad
Toss the value to avoid repeated bads. Do we toss new bad or old bad?
ELSE
Decide if the new value exceeds the archive compression deadband/
ELSE//
data quality is changed, flush held to disk
IF we have exceeded deadband or changed quality
// Store the old held sample in the archive
// Set up new deadband threshold using incoming value and value written to disk.
// Make the incoming value the held value